















.jpg "Get Timeform ratings for every upcoming runner and past result, plus premium winner-finders including commentary, Flags, Pace Maps and lots more.")


 Url copied to clipboard.
Url copied to clipboard.

The recent publication of an update to the Longines-sponsored World’s Best Racehorse Rankings (WBBRs) quite put the cat among the pigeons, with many racing fans aghast that Arrogate had retained his number-one position despite a third-successive defeat a few days earlier at the Breeders’ Cup.
It does not help that many of the obvious alternatives – such as Winx, Gun Runner and Enable – are as consistent as Arrogate has proved to be inconsistent. That trio have won, respectively, six, four and six races, most of them at the top level, since Arrogate gained what proved to be his final win (from Gun Runner, as it happens), in the Dubai World Cup in March.
There was a lot of heat but not a lot of light in the various commentary pieces on the situation, with few seeming to grasp that the WBRRs take into account form over the entire year and are guided by a horse’s best effort in that time. You cannot simply pretend that Dubai did not happen.
(video courtesy of MeydanRacing)
There is some truth in the observation that the WBRRs should really be called the “World’s Best Racehorse Performance”, though that is presumably a more difficult concept to sell. It also conveniently ignores the fact that a horse’s best recent effort is a powerful predictor of future achievement more generally.
There are alternatives to the attempt to define a racehorse by one peak effort, of course, and ratings systems might do well to give greater coverage to the array of performance ratings which go towards one over-arching master rating. A fuller picture allows the onlooker to weigh up matters of consistency, versatility and durability for themselves if they wish.
One alternative is to consider what would happen if a fictitious horserace were to take place, with each runner’s effort picked at random from its historical performance ratings over an agreed timescale. If you repeat the exercise often enough, you get a fair reflection of how often each horse “should” win based on the horses’ performance ratings (all of them, not just the peak ones).
The usual way of doing this is through what is known as a Monte Carlo Simulation, but it is feasible to cover all eventualities mathematically with a smaller sample.
First, you need to know what the horses’ array of performance ratings are. For this, I took the six most credible contenders for title of “Best Horse In The World” and extracted their Timeform assessments during 2017 for the first running of what may be called the Timeform Grand Prix.
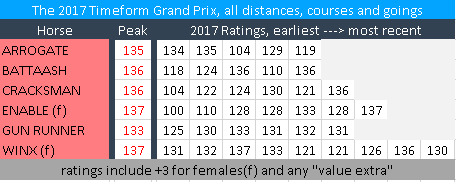
For the purpose of this exercise, the two females – Winx and Enable – have 3 added to each of their performance ratings to reflect the fact that they would receive a sex allowance if meeting male rivals in the real world. Those performance ratings also include Timeform “value extra” uplifts for ease of victory.
If you run every possible permutation of the “race”, sampling from each horse’s array of performance ratings, you get in excess of 50,000 unique contests. A rating of at least 125 is needed to win in every case, for each fictitious contest will have a Gun Runner in it running to 125 or higher.
The highest ratings – Enable’s 137 in winning the Prix de l’Arc de Triomphe at Chantilly and Winx’s 137 in winning the George Ryder at Rosehill – trump all others (besides when they meet each other and “dead heat”) but represent only 1/7 and 1/9 of those horses’ possible performances.
This is what the full simulation produces in terms of winning percentages across the 50,000+ races.
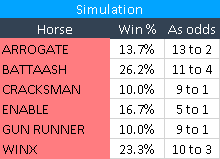
Each of the sextet could be expected to win at least 10% of the time, but it is Battaash who emerges victorious with a win-rate of 26.2%. That may come as a surprise!
Battaash ran only five times in 2017, but two of his wins (the King George at Goodwood and the Prix de l’Abbaye at Chantilly) were outstanding on Timeform figures. That is a larger proportion of performances at an elite level than the others.
Battaash’s other three performances won him none of the simulated races, but it is better to be hit or miss in such scenarios than to be worthily consistent: Gun Runner has more 130+ rated performances than any bar Winx, but they do not help him to many victories.
It might be argued that Enable’s first couple of performances (and Cracksman’s first) should be ignored, as she was not then the filly she later became. But it could also be argued that Arrogate’s and Battaash’s worst efforts should be excluded for being unrepresentative. In a review of a calendar year, all performances count.
Perhaps the enduring message is to recognise that an array of performance ratings gives a fuller picture of a horse’s achievements than one master rating alone, and reflects things like consistency and the number of times a certain level has been reached. But one master rating is needed, to determine weight carried in the real world, among other considerations.

Before finishing, it is worth commenting on those Battaash ratings, as he is the one top horse about which Timeform is in strong disagreement with the WBRRs (who has the horse on 123, the equivalent of 127 on Timeform’s longer-standing scale).
This comes down to the pounds-per-margin beaten in use by the respective ratings bodies as much as anything. It can be inferred from the BHA blog written after the Abbaye that just 18 lb per second was used (there was 0.95s between Battaash and fifth-placed Queen Kindly), which is an astonishingly small amount for a 5f race won in 57.59s.
Timeform used 26 lb per second, in line with its published methodology, which is sensitive to conditions and not fixed simply according to race distance. Esteemed author Bob Wilkins suggests this figure could be higher still.
The BHA’s “Guide To Handicapping” states an approximate pounds-per-length conversion of 3 lb per length at 5f, which is markedly out of line with most informed views on the matter. The discrepancy is significantly greater at distances short of a mile than at further.
There is empirical support for such an assertion, as those values do not more widely achieve the stated desire of equalising the chances of horses running in handicaps, in which last-time winners continue to win more often than last-time seconds, who continue to win more often than last-time thirds, and so on.
And those values most certainly undersell horses, like Battaash, who win top-class sprints by sizeable margins and in fast times, for it is almost impossible for them to win by far enough to get the sort of rating achieved by comparable horses at longer distances.
There is room for disagreement on exactly what Battaash should be rated, for sure, as there is on precisely how ratings define a horse’s ability more widely. But that he is a better horse than recognised officially appears as clear as day.

.jpg&w=300)

.jpg&w=300)
.jpg&w=300)

.jpg&w=300)































